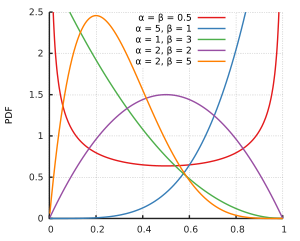
Beta-Verteilung für verschiedene ParameterwerteKumulative Verteilungsfunktion für verschiedene Parameterwerte
Die Beta-Verteilung ist eine Familie stetiger Wahrscheinlichkeitsverteilungen über dem Intervall , parametrisiert durch zwei Parameter, die häufig als p und q – oder auch als α und β – bezeichnet werden. In der bayesschen Statistik ist die Beta-Verteilung die konjugierte a-priori-Wahrscheinlichkeitsverteilung für die Bernoulli-, Binomial-, der negativen Binomial- und der geometrischen Verteilung.
Inhaltsverzeichnis
1Definition
2Eigenschaften
2.1Erwartungswert
2.2Modus
2.3Varianz
2.4Standardabweichung
2.5Variationskoeffizient
2.6Schiefe
2.7Höhere Momente
2.8Symmetrie
2.9Momenterzeugende Funktion
2.10Charakteristische Funktion
3Beziehungen zu anderen Verteilungen
3.1Spezialfälle
3.2Grenzfälle
3.3Beziehung zur Gammaverteilung
3.4Beziehung zur stetigen Gleichverteilung
3.5Mischverteilungen
4Beispiel
5Verallgemeinerung: Beta-Verteilung auf (a,b)
5.1Definition
5.2Eigenschaften
5.3Beispiel
6Einzelnachweise
7Weblinks
Definition
Die Beta-Verteilung ist definiert durch die Wahrscheinlichkeitsdichte
Außerhalb des Intervalls wird sie durch fortgesetzt. Für lässt sich durch ersetzen. Die Beta-Verteilung besitzt die reellen Parameter und (in den nebenstehenden Grafiken und ). Um ihre Normierbarkeit zu garantieren, wird (bzw. ) gefordert.
Der Vorfaktor dient der Normierung. Der Ausdruck
steht für die Betafunktion, nach der die Verteilung benannt ist. Dabei bezeichnet die Gammafunktion.
Die Verteilungsfunktion ist entsprechend
mit
Die Funktion heißt auch regularisierte unvollständige Betafunktion.
Eigenschaften
Erwartungswert
Der Erwartungswert berechnet sich zu
.
Modus
Der Modus, also die Maximalstelle der Dichtefunktion , ist für ,
.
Varianz
Die Varianz ergibt sich zu
.
Standardabweichung
Für die Standardabweichung ergibt sich
.
Variationskoeffizient
Aus Erwartungswert und Varianz erhält man unmittelbar den Variationskoeffizienten
.
Schiefe
Die Schiefe ergibt sich zu
.
Höhere Momente
Aus der momenterzeugenden Funktion ergibt sich für die k-ten Momente
.
Symmetrie
Die Beta-Verteilung ist für symmetrisch um mit der Schiefe .
Momenterzeugende Funktion
Die momenterzeugende Funktion einer betaverteilten Zufallsgröße lautet
.
Mit der hypergeometrischen Funktion erhält man die Darstellung
.
Charakteristische Funktion
Analog zur momenterzeugenden Funktion erhält man die charakteristische Funktion
.
Beziehungen zu anderen Verteilungen
Spezialfälle
Für ergibt sich als Spezialfall die stetige Gleichverteilung.
Für ergibt sich als Spezialfall die Arcsin-Verteilung.
Grenzfälle
Für und konstantes geht die Beta-Verteilung in eine Bernoulli-Verteilung über (eine entsprechende Zufallsgröße hat dann fast sicher den Wert null). Dasselbe gilt für bei konstantem .
Für und konstantes geht die Beta-Verteilung in eine Bernoulli-Verteilung über (eine entsprechende Zufallsgröße hat dann fast sicher den Wert eins). Dasselbe gilt für bei konstantem .
Beides sieht man leicht durch entsprechende Grenzwertbildungen der Formeln für Erwartungswert und Varianz: Der Erwartungswert geht gegen null bzw. eins, die Varianz beide Male gegen null.
Beziehung zur Gammaverteilung
Wenn und unabhängige gammaverteilte Zufallsvariablen sind mit den Parametern bzw. , dann ist die Größe betaverteilt mit Parametern und , kurz
Beziehung zur stetigen Gleichverteilung
Sind unabhängige auf stetig gleich verteilte Zufallsvariable, dann sind die Ordnungsstatistiken betaverteilt. Genauer gilt
Die Beta-Verteilung kann aus zwei Gammaverteilungen bestimmt werden: Der Quotient aus den stochastisch unabhängigen Zufallsvariablen und , die beide gammaverteilt sind mit den Parametern und bzw. , ist betaverteilt mit den Parametern und . und lassen sich als Chi-Quadrat-Verteilungen mit bzw. Freiheitsgraden interpretieren.
Mit Hilfe der linearen Regression wird eine geschätzte Regressionsgerade durch eine „Punktwolke“ mit Wertepaaren zweier statistischer Merkmale und gelegt, und zwar so, dass die Quadratsumme der senkrechten Abstände der -Werte von der Geraden minimiert wird.
Die Streuung der Schätzwerte um ihren Mittelwert kann durch gemessen werden und die Streuung der Messwerte um ihren Mittelwert kann durch gemessen werden. Erstere stellt die „(durch die Regression) erklärte Quadratsumme“ (sum of squares explained, kurz: SSE) und letztere stellt die „totale Quadratsumme“ (sum of squares total, kurz: SST) dar. Der Quotient dieser beiden Größen ist das Bestimmtheitsmaß:
.
Die „(durch die Regression) nicht erklärte Quadratsumme“ bzw. die „Residuenquadratsumme“ (residual sum of squares, kurz SSR) ist durch gegeben. Durch die Quadratsummenzerlegung lässt sich das Bestimmtheitsmaß auch darstellen als
.
Es ist also betaverteilt. Da das Bestimmtheitsmaß das Quadrat des Korrelationskoeffizienten von und darstellt (), ist auch das Quadrat des Korrelationskoeffizienten betaverteilt. Allerdings kann die Verteilung des Bestimmtheitsmaßes beim globalen F-Test durch die F-Verteilung angegeben werden, die tabelliert vorliegt.
Verallgemeinerung: Beta-Verteilung auf (a,b)
Definition
Die allgemeine Beta-Verteilung ist definiert durch die Wahrscheinlichkeitsdichte
wobei und die obere und untere Grenze des Intervalls sind. Entsprechend ergibt sich die Berechnung von zu
Eigenschaften
Ist betaverteilt auf dem Intervall mit Parametern , , dann ist
betaverteilt auf dem Intervall mit den gleichen Parametern , . Ist umgekehrt betaverteilt auf , dann ist
betaverteilt auf .
Beispiel
Im Dreieckstest werden drei Proben im gleichseitigen Dreieck angeordnet, wobei eine Ecke des gedachten Dreiecks nach oben zeigt. Zwei der drei Proben gehören zum Produkt A und eine Probe gehört zum Produkt B oder umgekehrt. Die Aufgabe des Probanden besteht nun darin, dasjenige Produkt zu finden, das nur einmal vorkommt. Die Wahrscheinlichkeit durch bloßes Raten die richtige Antwort zu geben beträgt .
Verteilung der Erfolgswahrscheinlichkeiten einer Stichprobe im Dreieckstest (schwarze Linie) bei einer Rate-Erfolgswahrscheinlichkeit von (blaue Linie)
Die Erfolgswahrscheinlichkeiten variieren je nach sensorischen Fähigkeiten. Unter der Annahme, dass kein Proband absichtlich eine falsche Antwort gibt, liegt die Erfolgswahrscheinlichkeit bei niemandem unter . Bei Feinschmeckern oder großen Geschmacksunterschieden kann diese theoretisch bis auf 100 % ansteigen. Im Folgenden wird für beliebige Rate-Erfolgswahrscheinlichkeiten mit die Beta-Verteilung auf hergeleitet.[1] Aus den eben genannten Gründen modelliert diese Wahrscheinlichkeitsdichte die Erfolgswahrscheinlichkeiten der Probanden realistischer als eine Beta-Verteilung auf .
Die Erfolgswahrscheinlichkeiten der einzelnen Probanden seien zunächst betaverteilt auf mit Parametern und . Die korrigierten Erfolgswahrscheinlichkeiten auf ergeben sich aus . Die Wahrscheinlichkeitsdichte von lässt sich über den Transformationssatz für Dichten bestimmen. Die Beta-Verteilung von hat eine positive Dichte im Intervall . Die Transformation mit ist ein Diffeomorphismus. Daraus erhält man die Umkehrfunktion . Für die gesuchte Dichtefunktion von erhält man
.
Diese Wahrscheinlichkeitsdichte von auf wird in Abhängigkeit von der Wahrscheinlichkeitsdichte von auf dargestellt. In der nebenstehenden Grafik ist beispielhaft eine Beta-Verteilung auf mit Parametern und eingezeichnet. Der Erwartungswert beträgt . Die durchschnittliche Erfolgswahrscheinlichkeit liegt damit über der Rate-Erfolgswahrscheinlichkeit von .
Einzelnachweise
↑Brockhoff, Per Bruun. "The statistical power of replications in difference tests." Food Quality and Preference 14.5 (2003): 405-417.
Weblinks
Sigrid Markstein: Mathematische und rechentechnische Aufbereitung der Betaverteilung 1. Art für technologische Untersuchungen.






![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)










































































































