Konzisztens becslés
A statisztikában a konzisztens becslés vagy aszimptotikusan konzisztens becslés egy becslés – a θ0 paraméter valós értékének kiszámítására szolgáló szabály –, amelynek az a tulajdonsága, hogy ahogy a felhasznált adatpontok száma korlátlanul növekszik, a kapott becslések sorozatának valószínűségi határértéke (plim) θ0-hoz konvergál. Ez azt jelenti, hogy a becslések eloszlása egyre inkább a becsült paraméter valódi értékéhez közel koncentrálódik, így annak valószínűsége, hogy a becslő tetszőlegesen közel kerül θ0-hoz, egyhez konvergál.
A gyakorlatban ez úgy működik hogy készítünk egy becslést egy rendelkezésre álló n méretű minta alapján, majd elképzeljük, hogy tovább gyűjthetjük az adatokat, és a végtelenségig bővíthetjük a mintát. Ily módon n-nel indexelt becslések sorozatát kapjuk, és a konzisztencia arra vonatkozik, hogy mi történik akkor, ha a minta mérete „a végtelenségig nő”. Ha a becslések sorozata matematikailag kimutathatóan valószínűségében konvergál a valódi θ0 értékhez, akkor konzisztens becslésnek nevezzük; ellenkező esetben a becslést inkonzisztensnek mondják.
Az itt meghatározott konzisztenciát néha gyenge konzisztenciának is nevezik. Ha a valószínűségi konvergenciát majdnem biztos konvergenciával helyettesítjük, akkor a becslés erősen konzisztensnek mondható. A konzisztencia a torzítottsághoz hasonló fogalom, mivel mindkettő azt méri hogy egy becslés mennyire „jó” - azonban két különböző szempontból - fontos hogy egyik tulajdonságból sem következik a másik.
Definíció
Formálisan egy becslés T n a θ paraméterre akkor konzisztens, ha valószínűségben konvergál a valódi paraméterhez: [1]

azaz, ha minden ε > 0 esetén

Egy szigorúbb definíció figyelembe veszi azt a tényt, hogy θ értéke valójában ismeretlen, így a valószínűségi konvergenciának meg kell történnie e paraméter minden lehetséges értékére. Tegyük fel, hogy {pθ: θ ∈ Θ } eloszlások egy halmaza (a parametrikus modell ), és Xθ = {X1, X2, … : Xi ~ pθ } egy végtelen minta a p θ eloszlásból. Legyen { T n ( X θ ) } becslések sorozata valamilyen g ( θ ) paraméterhez. Általában a T n egy minta első n megfigyelésén alapul. Ekkor ezt a { T n } sorozatot (gyengén) konzisztensnek mondjuk, ha [2]

Ez a definíció egy g (θ) függvényt használ θ helyett, mivel az embert gyakran érdekli az alapul szolgáló paraméter egy bizonyos függvényének vagy egy részvektorának becslése.
Példák
Normál valószínűségi változó mintaátlaga
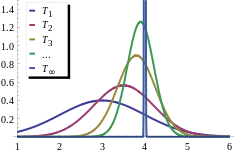
Tegyük fel, hogy van egy {X1, X2, ...} megfigyelési sorozatunk egy normál N (μ, σ2) eloszlásból. A μ első n megfigyelés alapján történő becsléséhez a mintaátlagot használhatjuk: . Ez meghatározza a becslések sorozatát, az n mintamérettel indexelve.

A normális eloszlás tulajdonságaiból ismerjük ennek a statisztikának a mintavételi eloszlását : T n maga normális eloszlású, μ átlaggal és σ 2 / n szórással. Ezzel egyenértékűen sztenderd normál eloszlású:

![{\displaystyle \Pr \!\left[\,|T_{n}-\mu |\geq \varepsilon \,\right]=\Pr \!\left[{\frac {{\sqrt {n}}\,{\big |}T_{n}-\mu {\big |}}{\sigma }}\geq {\sqrt {n}}\varepsilon /\sigma \right]=2\left(1-\Phi \left({\frac {{\sqrt {n}}\,\varepsilon }{\sigma }}\right)\right)\to 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1427f3a9408cdda24cd8bfd6187fd3159d686ea1)
ahogy n a végtelenhez tart, bármely rögzített ε > 0 számra. Ezért a mintaátlagok T n sorozata konzisztens a sokaság átlagára nézve μ ( a normális eloszlás kumulatív eloszlás függvénye).

A konzisztencia vizsgálata
Az aszimptotikus konzisztencia fogalma nagyon közel áll, szinte szinonimája a valószínűségi konvergencia fogalmának. Mint ilyen, bármely tétel, lemma vagy tulajdonság, amely valószínűségi konvergenciát állapít meg, felhasználható a konzisztencia bizonyítására. Számos ilyen eszköz létezik:
- A konzisztencia közvetlenül a definícióból való bizonyítására használhatjuk a következő egyenlőtlenséget [3]
![{\displaystyle \Pr \!{\big [}h(T_{n}-\theta )\geq \varepsilon {\big ]}\leq {\frac {\operatorname {E} {\big [}h(T_{n}-\theta ){\big ]}}{h(\varepsilon )}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2f85b6918244bbc21064136cadbed4a801549fad)
a h függvény leggyakrabban vagy az abszolút érték (ebben az esetben ez a reláció Markov-egyenlőtlenségként ismert), vagy a négyzet függvény (ekkor ez a Csebisev-egyenlőtlenség ).
- Egy másik hasznos eredmény a folytonos leképezési tétel : ha T n konzisztens θ-re, és g (·) egy valós értékű függvény amely folytonos a θ pontban, akkor g ( T n ) konzisztens lesz g( θ )-re: [4]

- Szluckij tétele használható több különböző becslés kombinálására, vagy egy becslés nem véletlenszerű konvergens sorozatával. Ha T n → d α és S n → p β, akkor [5]

- Ha a T n becslést egy explicit képlettel adjuk meg, akkor a képlet valószínűségi változók összegét fogja használni, és ekkor a nagy számok törvénye használható: { X n } valószínűségi változók sorozatára megfelelő feltételek mellett igaz hogy
![{\displaystyle {\frac {1}{n}}\sum _{i=1}^{n}g(X_{i})\ {\xrightarrow {p}}\ \operatorname {E} [\,g(X)\,]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/10b736680a0d0837ea1290104d9acca589aa63f4)
- Ha a T n becslés implicit módon van definiálva, például olyan értékként, amely maximalizál egy bizonyos célfüggvényt (lásd extrémumbecslő), akkor bonyolultabb, sztochasztikus ekvikontinuitást magában foglaló bizonyítást kell használni. [6]
Torzítottság versus konzisztencia
Torzítatlan, de nem konzisztens
A becslő lehet torzítatlan, de nem konzisztens. Például egy {x1, ..., xn} iid mintához használható a Tn (X) = xn mint az E[x] átlag becslője. Vegyük figyelembe, hogy itt a Tn mintavételi eloszlása megegyezik a mögöttes eloszlással (bármely n esetén, mivel figyelmen kívül hagy minden pontot, kivéve az utolsót), így E[ Tn(X)] = E[x] és torzítatlan, de nem konvergál semmilyen értékhez.
Ha azonban a becslések sorozata torzítatlan és konvergens értékhez, akkor konzisztens, mivel a helyes értékhez kell konvergálnia.
Torzított, de konzisztens
Másrészről a becslés lehet torzított, de konzisztens. Például, ha az átlagot a következővel becsüljük meg: akkor ez a becslés torzított, de ahogy , megközelíti a helyes értéket, és így konzisztens.


Fontos példa a minta varianciája és a minta szórása. A Bessel-korrekció nélkül (vagyis a mintaméret helyett a szabadságfokot használjuk normalizálásra), is negatívan torzított, de konzisztens becslés. A korrekcióval a korrigált minta varianciája torzítatlan, míg a korrigált minta szórása továbbra is torzított, de kevésbé, és mindkettő továbbra is konzisztens: a korrekciós tényező 1-hez konvergál a minta méretének növekedésével.


Íme egy másik példa. Legyen becslések sorozata -re:



Láthatjuk, hogy , , és a torzítás nem konvergál nullához.

![{\displaystyle \operatorname {E} [T_{n}]=\theta +\delta }](https://wikimedia.org/api/rest_v1/media/math/render/svg/88d36066b1ca8f168ef6c72d6650e8eedcf80d22)
Jegyzetek
- ↑ Amemiya 1985, Definition 3.4.2.
- ↑ Lehman & Casella 1998.
- ↑ Amemiya 1985, equation (3.2.5).
- ↑ Amemiya 1985.
- ↑ Amemiya 1985, Theorem 3.2.7.
- ↑ Newey & McFadden 1994, Chapter 2.
Fordítás
Ez a szócikk részben vagy egészben a Consistent estimator című angol Wikipédia-szócikk ezen változatának fordításán alapul. Az eredeti cikk szerkesztőit annak laptörténete sorolja fel. Ez a jelzés csupán a megfogalmazás eredetét és a szerzői jogokat jelzi, nem szolgál a cikkben szereplő információk forrásmegjelöléseként.






